TAG
CTF 리버싱 입문자를 위한 가이드
0. 들어가기에 앞서…
0-0. 제작한 이유
제작한 이유는 간단하다. 내가 리버싱을 처음 시작했을 때는, 어느 한 책에서 리버스 엔지니어링 파트를 보고 시작을 했다. 본격적으로 공부를 시작했지만, 혼자 공부를 하면서 여러 어려움들을 겪었고, 직접 부딪혀 가며 습득했던 노하우, 그리고 공부방법을 내가 겪었던 어려움들을 조금이나마 덜어주기 위해 제작하게 되었다.
물론 나는 아직 공부를 진행하는 일게 학생일 뿐이며, 나보다 우수한 사람은 너무나 많기 때문에, 내가 작성한 이 가이드는 참고용으로 써주길 바란다.
0-1. 리버싱의 본질?
내가 생각하는 리버싱의 본질에 대해 설명하기 전에, 보통 CTF 리버싱 문제는 주로 완성된 프로그램(binary) 형태로 주어진다. 따라서 앞으로 내가 리버싱이라 일컷고, 설명할 것은 Binary 리버싱에 대한 것임을 참고 바란다.
(현재로선) 모든 프로그램(Binary)는 사람(프로그래머)가 만든다. 또한, 프로그램의 특성상, 어떤 목적에 의해 만들어 진 것이며, 프로그래머는 그 목적에 맞게 프로그래밍을 하게 된다. 프로그래머 또한 사람이다. 목적에 맞게 프로그램을 만드는 과정에서, 제작자는 스스로의 의도를 코드로 작성하게 된다. Binary Reversing을 진행을 하면, 리버서는 제작자의 의도를 읽고, 분석하고, 파악하게 된다.
이때, 더 나아가 리버서는 자신의 의도를 덧 씌울 수 있는 정도로 분석을 진행 할수 있게 된다.
따라서 내가 생각하는 리버싱(Binary Reversing)의 본질이란, 제작자(프로그래머)의 의도를 분석하는 것을 넘어, 자신의 의지를 덧 씌우는 것이라 생각한다
0-2. 필요 배경지식.
필수 배경지식
어셈블리어- C언어
- 메모리 구조
- 함수 호출 규약
추가 배경지식
- 알고리즘
- 자료구조
이중, C언어는 기본적으로 알고 있다는 전제하에, 글이 작성되었음을 밝힌다. 어셈블리어는 아래에서 설명을 할 것이다.
챕터 0. 리버싱(리버스 엔지니어링)이란
리버스 엔지니어링(Reverse Engineering)은 직역하면 역공학으로, 소프트웨어를 다루는 사람들에겐 완성된 프로그램(바이너리)를 분석하는 것으로 알려져 있다.
하지만, 역공학은 엄밀히 말하면 소프트웨어에 한정된 것이 아니다. 장치 혹은 시스템의 기술적인 원리를 구조분석하을 통해 발견하는 과정 그 자체를 말한다. 즉 기계 장치, 전자 부품 그리고 소프트웨어를 조각내서 분석하는 것을 포함하며, 유지 보수를 위해 같은 기능을 하는 새 장치를 기존의 것을 사용하지 않고 만들기 위해 세부적인 작동을 분석하는 것도 포함한다.
우리가 흔히 보는 Logitech Crayon같은 제품의 경우도, reverse engineering으로 탄생했다고 볼 수 있을 것이며, 프로그램의 crack버전도 reverse engineering을 통해 탄생한 것들이다.
하지만 우리는 CTF를 위해 리버싱을 입문하는 만큼(앞서 말했듯), 이 문서에선 Binary Reversing을 다룰 것이다. (기본적인 C언어는 안다는 가정하에 진행하니 참고하자.)
챕터 1. 리버싱 입문하기.
1-0 리버싱 공부방법
리버싱은 사고력, 분석력 싸움이다. 따라서 리버싱을 배울때 사고력과 분석력을 기르는 방향으로 공부를 진헹 하여야 한다.
즉, 단순 문제 해결에만 치중하면 안되며, 결국에 리버싱의 본질에 보다 다가가기 위해서는, Binary(machine code)를 우리가 읽을 수 있는 언어로 바꾸는 과정들을 꾸준히 연습해야 한다.
리버싱 solve 방법은 여러가지가 있다. Brute Force, Patch 등이 있겠지만, 리버싱 공부는 저 두가지 방법 보단, 분석을 통한 소스 코드 복원이 주가 되어야 할 것이다.
그리고, 끈기가 가장 중요하다. 남의 의도(생각)을 읽고 분석하는 과정인 만큼, 쉽지 않음을 명심하고 포기하지 말고 의도를 정복할 때까지 진행하겠다는 마음가짐이 필요하다.
이 두가지를 명심한다면, 여러분도 리버싱을 쉽게 진행할 수 있게 될 것이다.
1-1 어셈블리어란
모두가 알고있듯, 컴퓨터는 전기로 작동되기 때문에, 0, 1의 이진수로만 작동한다.
컴퓨터의 두뇌인 CPU에서는, 우리가 요하는 각종 연산 등을 0, 1로만 처리해야만 한다.
따라서 CPU 제조사에서는, CPU가 다른 장치에게 명령들을 내리고, 연산을 하기 위해, 이진수로 이루어진 신호체계(명령 체계)를 만들어 CPU에 탑제하여 제공하게 되며, 메뉴얼과 함께 제공을 한다.
이를 명령어 집합(Instruction set Architecture (ISA))라고 부르며, 이는 CPU 구조(CPU Architecture)별로 상이하다. 여기에는 각종 명령 뿐 아니라, 현재 시스템의 상태가 어떻게 구성되어 있는지, 명령어들이 실행될 때 그 상태가 어떻게 바뀌는지에 대해서도 정의되어있다.
ISA의 이진 명령어들은, 기계어(machine code)라고도 부르며, opcode(명령의 종류), operand(opcde의 피연산자)로 구성되어 있다,
하지만, ISA로 직접 복잡한 프로그램을 구성하기에는 너무 힘들기 때문에, 기계어와 1대1 대응되는 High Level Language가 존재하며, 이를 어셈블리어(Assembly)라고 한다.
길게 설명했지만, 요약하면 어셈블리어(Assembly)는, 해당 CPU의 명령셋에 1대1로 대응되는 프로그래밍 언어이다.
1-2 80x86 어셈블리어
대부분의 PC는 현재 Intel사, AMD사의 CPU를 사용한다.
intel사와, AMD사의 CPU는 CISC ISA를 사용하고 있고, ARM Architecture를 사용하는 CPU들은 RISC ISA를 사용하고 있는데, 이를 간단하게 설명하자면, CISC ISA의 특징은 다양하고 복잡하고, 가변적으로 사용할 수 있는 명령어로 이루어져 있다는 것이며(그나마 인간에게 편함), RISC ISA는 일정한 명령어 길이, 메모리(RAM)보다는 Register사용 등의 특징이 있는데, 이 때문에 RISC ISA로 프로그램을 만드는 것은 CISC ISA 보다 힘들었다. (명령어 길이가 제한적), 따라서 프로그래머들은 CISC ISA를 선호하게 되었고, 이에 intel사의 CPU를 사용한 PC의 보급률이 높아졌다. (사실 Intel CPU의 점유률이 너무 높아 강제로 Intel을 사용할 수 밖에 없는 것도 컸다.)
intel사의 Architecture인 x86이 처음 나온 프로세서는 8086프로세서(1978년)안데, 그 뒤로부터 해당 Architecture를 차용한 프로세서 시리즈들이, 80으로 시작해서 86으로 끝났기 때문에, 80x86으로 부르게 되었다.
x86 Architecture는 32bit 기반이며, AMD사에서 64bit 확장을 처음 했기 때문에, amd64로 64bit Architecture가 존재하게 되었다.
해당 장에서는, x86, amd64 Assembly를 혼용하여 설명할 것임을 밝힌다.
Assembly에서 중요하게 알아야 할 것은, 함수의 호출 규약과, 피연산자로 쓰이는 레지스터(Register)들의 역할이다. (32bit, 64bit 프로세서를 나누는 기준이 되는 것이 Register가 한번에 처리할 수 있는 최대 bit이다.)
x86 Register
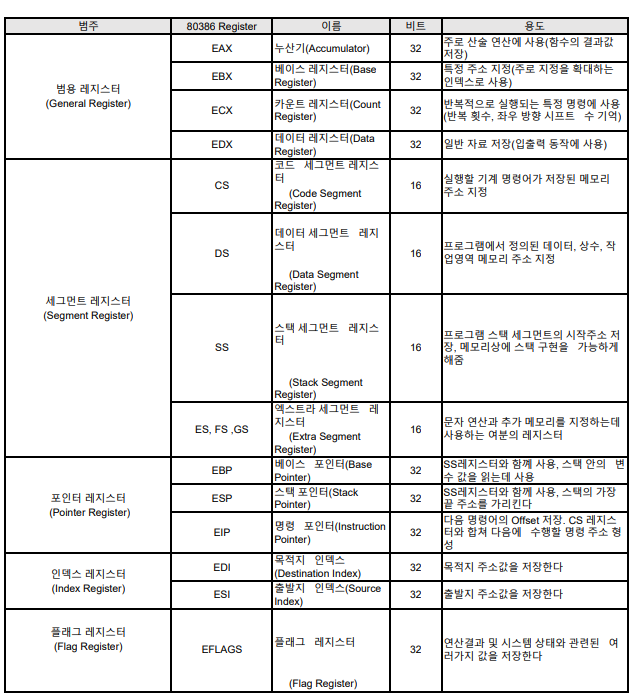
[Image - x86 Register]

[Image - x86 General Register Detail]
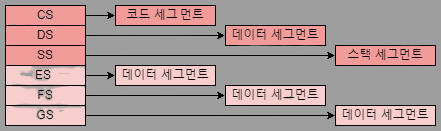
[Image - x86 Segment Register Detail]
정리한 x86 Register의 역할과 명칭들이다. 64bit는 해당 32bit Register의 확장형 이므로 따로 정리하진 않겠다,
Assembly Hello World로 이해하기
section .data
welcome db "Hello, World!"
section .text
global _start
_start:
mov eax, 0x4; write
mov ebx, 1; stdout
mov ecx, welcome; buf
mov edx, 0xd; message length
int 0x80; call write
mov eax, 0x1; exit
mov ebx, 0x0; error code
int 0x80; call exit
[Code - HelloWorld_32bit.s]
section .data
welcome db "Hello, Wolrd!"
section .text
global _start
_start:
mov rax, 1; sys_write
mov rdi, 1; stdout
mov rsi, welcome; buf
mov rdx, 0xd; message length
syscall; calling sys_write
mov rax, 0x3c; sys_exit
mov rdi, 0x0; error_code
syscall; calling sys_exit with error_code
[Code - HelloWorld_64bit.s]
위의 두 코드는 위에서부터, x86 Architecture, amd64 Architecture로 작성된 Hello,World 출력 프로그램이다.
Assembly에도 여러 문법이 존재하는데, x86기반의 Assembly의 경우, 대표적으로 AT&T문법과, intel문법이 존재한다.(위의 코드는 intel 문법으로 작성되었으며, intel 문법 기반으로 문서는 작성한다.)
.data
welcome:
.string "Hello world!"
.text
.globl _start
_start:
movl $4, %eax
movl $1, %ebx
movl $welcome, %ecx
movl $0xd, %edx
int $0x80
movl $1, %eax
movl $0, %ebx
int $0x80
[Code - x86_AT&T Grammer Hello World](AT&T 문법 코드 예제)**
intel 문법의 경우 요약하면 다음처럼 해석된다.(AT&T 문법은 반대로 해석)
opcode operand1(, operand2) → operand1에 opcode를 적용한다, operand1, operand2에 opcode를 적용한다.(적용한 결과를 operand1에 저장한다.)
앞서, Assembly는 opcode와 operand로 이루어진다고 했다싶이, _start 프로시저에서 첫번째 라인인 mov eax, 0x4; write를 볼 경우, opcode는 movoperand는 eax와 0x4이다.
위처럼 해석을 하면, 이는 EAX에 0x4를 mov(저장)해라.라는 의미로 해석되는 것이다.
기초 Opcode
| Opcode | 문법 | 의미 |
|---|---|---|
| call | call OPERAND | 함수 호출 |
| ret | ret | 호출된 함수 종료, 호출된 다음 명령줄로 이동(return) |
| nop | nop | 아무것도 하지 않음 |
| cmp | cmp OPERAND1, OPERAND2 | OPERAND1, OPERAND2을 값의 차로 비교. 결과값 저장됨. 값이 같으면 ZF 1로 세팅 |
| test | test OPERAND1, OPERAND2 | OPERAND1, OPERAND2을 bit and 연산을 이용해 비교. 결과값 저장 안됨. and 연산 결과가 0이면 ZF 1로 세팅 |
| jmp | jmp OPERAND | OPERAND로 이동(jump) |
| je | je OPERAND | cmp A, B에서 A == B일때 jmp. |
| jne | jne OPERAND | cmp A, B에서 A != B일때 jmp. |
| ja | ja OPERAND | cmp A, B에서 A > B일때 jmp. |
| jb | jb OPERAN | cmp A, B에서 A < B일때 jmp. |
| jae | jae OPERAND | cmp A, B에서 A ≥ B일때 jmp. |
| jbe | jbe OPERAND | cmp A, B에서 A ≤ B일때 jmp. |
| jz | jz OPERAND | ZF가 1로 세팅 되었을 때 jmp. |
| jnz | jnz OPERAND | ZF가 0으로 세팅 되었을 때 jmp. |
| push | push OPERAND | OPERAND 의 값을 메모리 스택에 푸쉬 |
| pop | pop OPERAND | OPERAND에 스택의 값을 가져오고 대입. 이후 STACK POINTER는 증가(스택 영역 크기 감소) |
| mov | mov OPERAND1, OPERAND2 | OPERAND1에 OPERAND2의 값을 대입. |
| lea | lea OPERAND1, OPERAND2 | OPERAND1에 OPERAND2의 주소를 대입. |
| inc | inc OPERAND | OPERAND의 값을 1 증가 |
| dec | dec OPERAND | OPERAND의 값을 1 감소 |
| add | add OPERAND1, OPERAND2 | OPERAND1 + OPERAND2 결과값을 OPERAND1에 저장 |
| sub | sub OPERAND1, OPERAND2 | OPERAND1 - OPERAND2 결과값을 OPERAND1에 저장 |
| div | div OPERAND1, OPERAND2 | OPERAND1 / OPERAND2 결과값을 OPERAND1에 저장(몫). 나머지는 64bit기준 rdx에 저장. |
| imul | imul OPERAND1, OPERAND2 | OPERAND1 * OPERAND2 결과값을 OPERAND1에 저장 |
| shr | shr OPERAND1, OPERAND2 | OPERAND1의 값을 OPERAND2의 값만큼 오른쪽 비트 쉬프트. |
| shl | shl OPERAND1, OPERAND2 | OPERAND1의 값을 OPERAND2의 값만큼 왼쪽 비트 쉬프트. |
| int 0x80(32bit) | int 0x80 | eax에 저장되어 있는 값을 기준으로, system call 호출 |
| syscall(64bit) | syscall | rax에 저장되어 있는 값을 기준으로, system call 호출 |
Assembly 코드해석
section .data welcome db "Hello, Wolrd!"
해당 코드는 data 섹션을 정의하고, welcome이라는 변수 명에 byte 데이터로 “Hello, World!” 문자열을 저장한다.
section .text global _start
해당 라인에선, C에서의 main함수 처럼, 실제 프로그램의 시작 부분인 _start 프로시저를 명시한다.
_start: 해당 부분에선 _start 프로시저의 코드가 정의된다.
mov rax, 1; sys_write (;이후 부분은 주석) rax에 출력을 위한 syscall인 1을 저장한다. (linux syscall table 참조)
mov rdi, 1; stdout mov rsi, welcome; buf mov rdx, 0xd; message length syscall; calling sys_write
위 라인은 sys_write에 들어갈 인자들을 세팅한다. C 의 write(1, welcome, 0xd)와 동일하다고 보면 된다.
mov rax, 0x3c; sys_exit mov rdi, 0x0; error_code syscall; calling sys_exit with error_code`
위 라인은 sys_exit를 호출하여 프로그램의 정상적인 종료를 진행하는 부분이다, C의 exit(0)와 동일하다고 보면 된다.
해당 코드를 위처럼 따라가면서 분석을 진행했다면, 실행 결과는 화면에 Hello, World!가 출력될 것이며, 프로그램의 종료 코드는 0임을 짐작 할 수 있다.
이처럼 직접 코드를 실행해가면서 분석하는 것을 정적 분석이라고 한다.
위의 정적 분석 결과를 우리가 훨씬 쉽게 읽을 수 있는 C코드로 변환하게 되면 다음처럼 될 것이다.(소스 코드 복원)
#include <stdio.h>
int main(void)
{
write(1, "Hello World!". 0xd);
exit(0);
}
동적분석
지금은 툴 설명을 안했기 때문에, 읽어가면서 따라하면 된다. (pwndbg 사용, WSL 환경에서 진행하였다.)
- 컴파일
nasm -f elf64 HelloWorld_64bit.s && ld -o HelloWorld_64bit HelloWorld_64bit.o
nasm -f elf32 HelloWorld_32bit.s && ld -m elf_i386 -o HelloWorld_32bit HelloWorld_32bit.o
gdb 실행 gdb ./HelloWorld_64bit
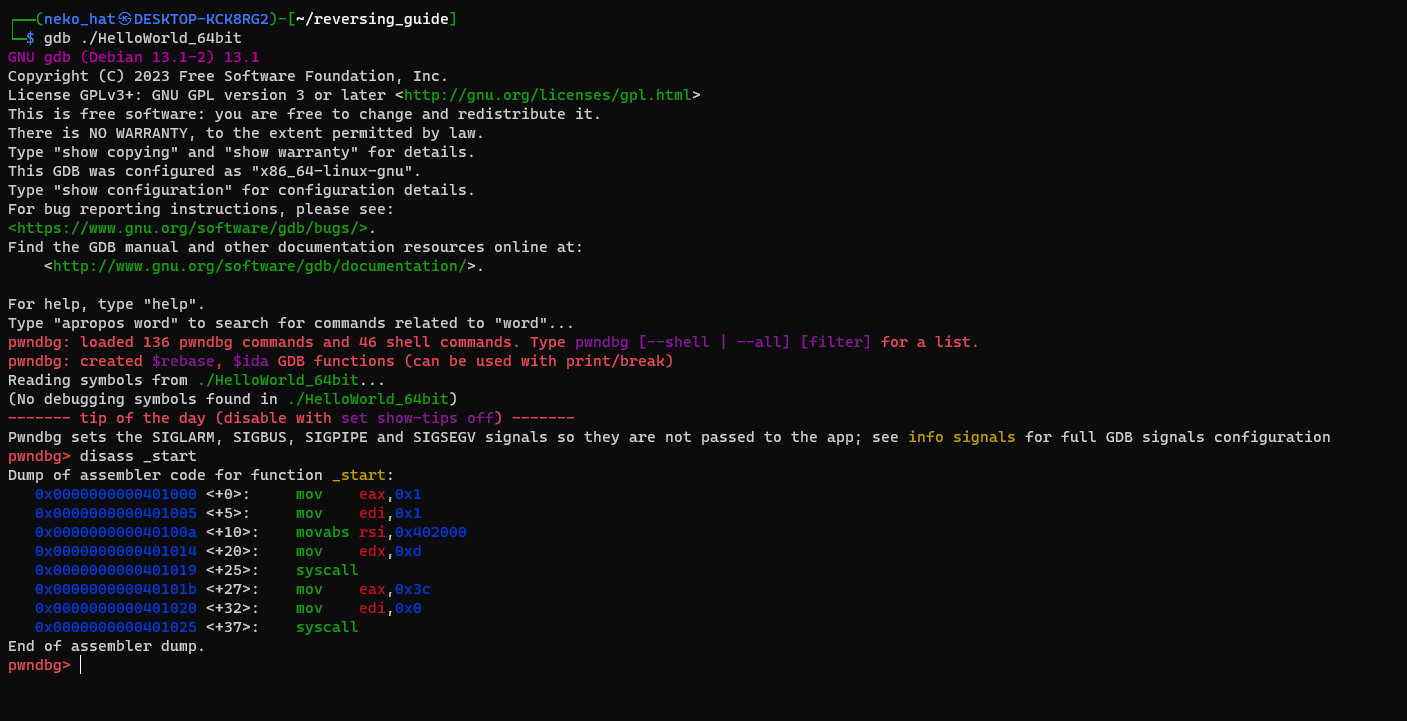
disass _start명령어를 통해, 작성한 _start 프로시저의 디스어셈블 코드를 확인 할 수 있다.
n(next)명령어를 통해, 코드를 한줄 한줄 실행해보자.
pwndbg> b _start → break point를 _start 프로시저에 걸어보자.
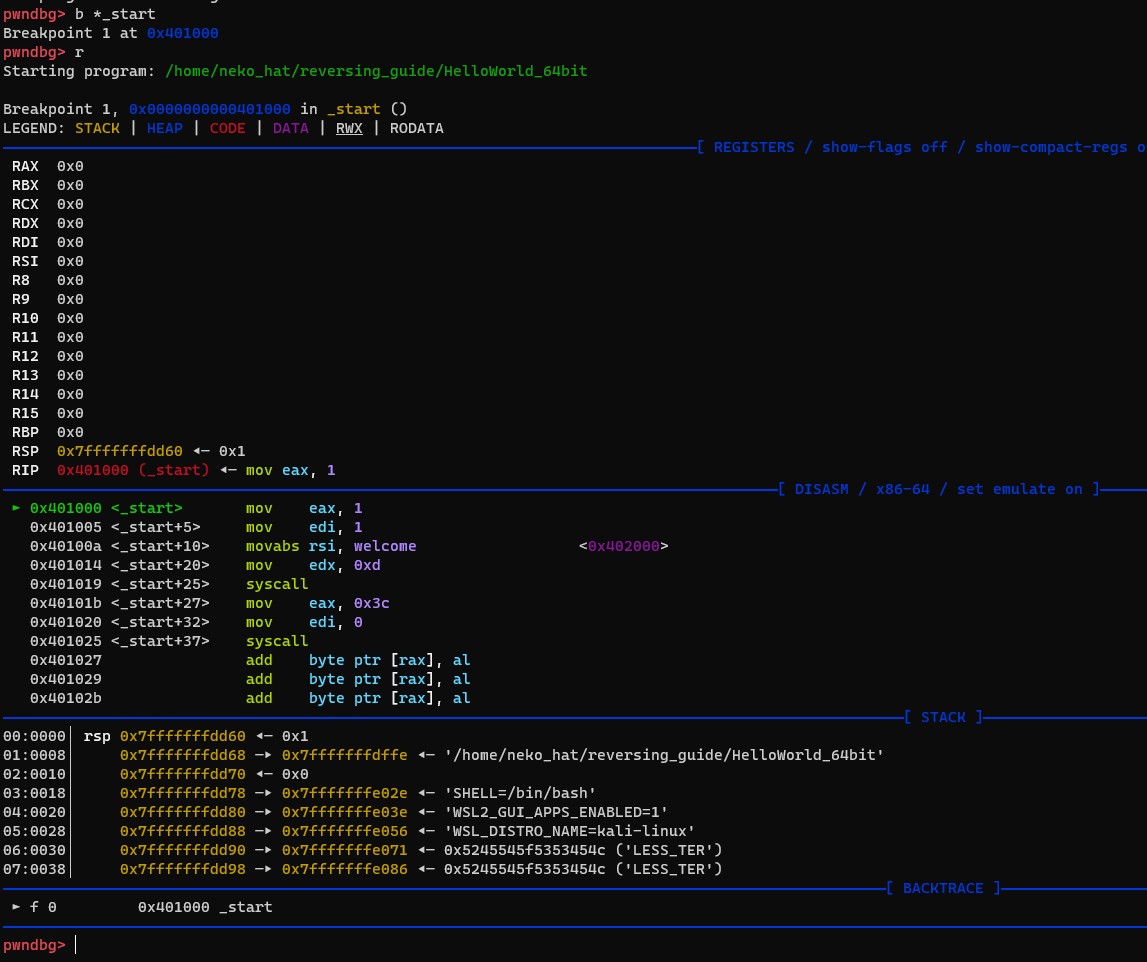
이후, r(run)명령어로 프로그램을 실행하면, 해당 프로시저 진입에서 멈추는 것을 확인할 수 있다.
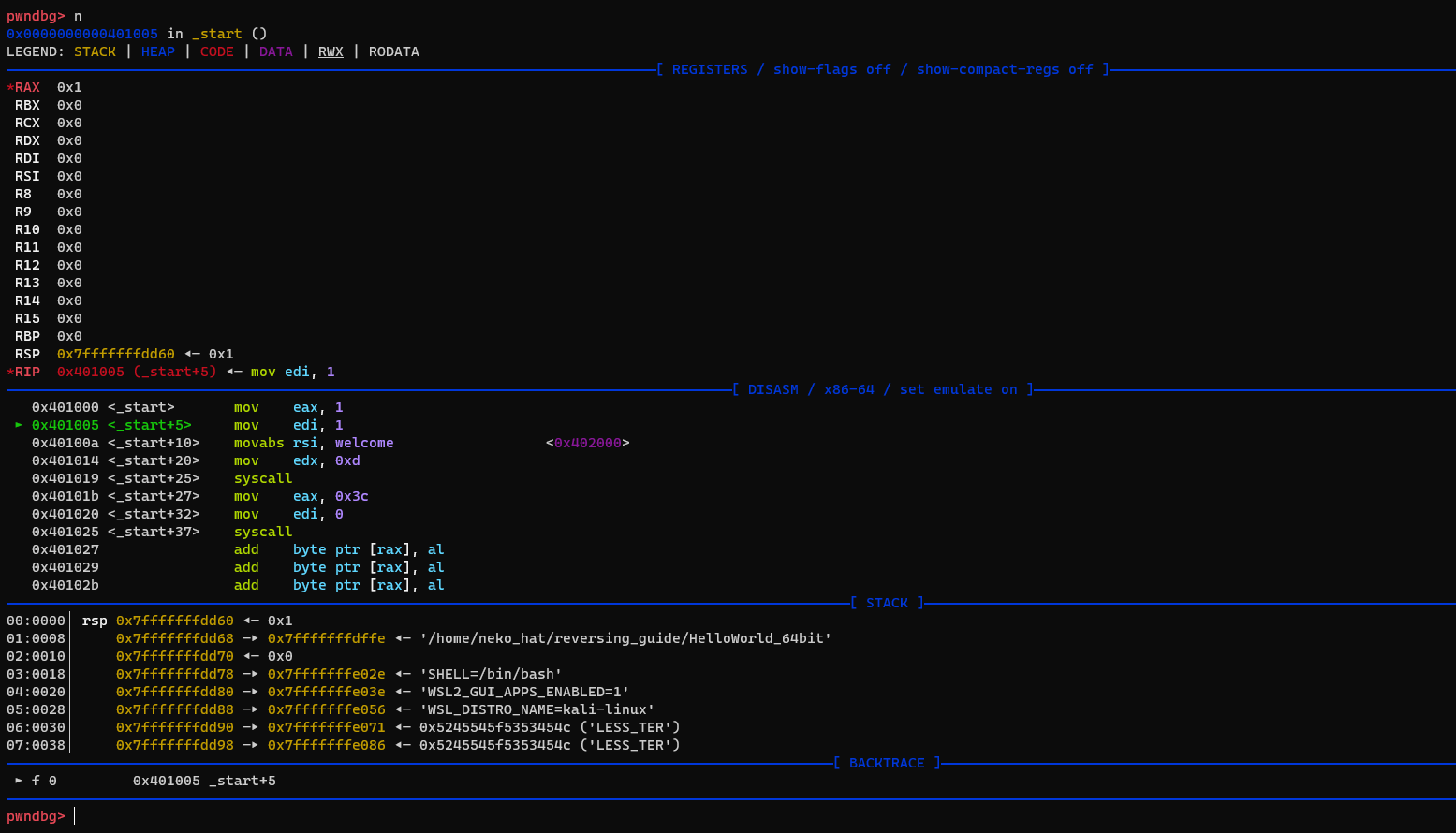
n명령어로, 단계별 실행결과를 바로바로 확인할 수 있다.
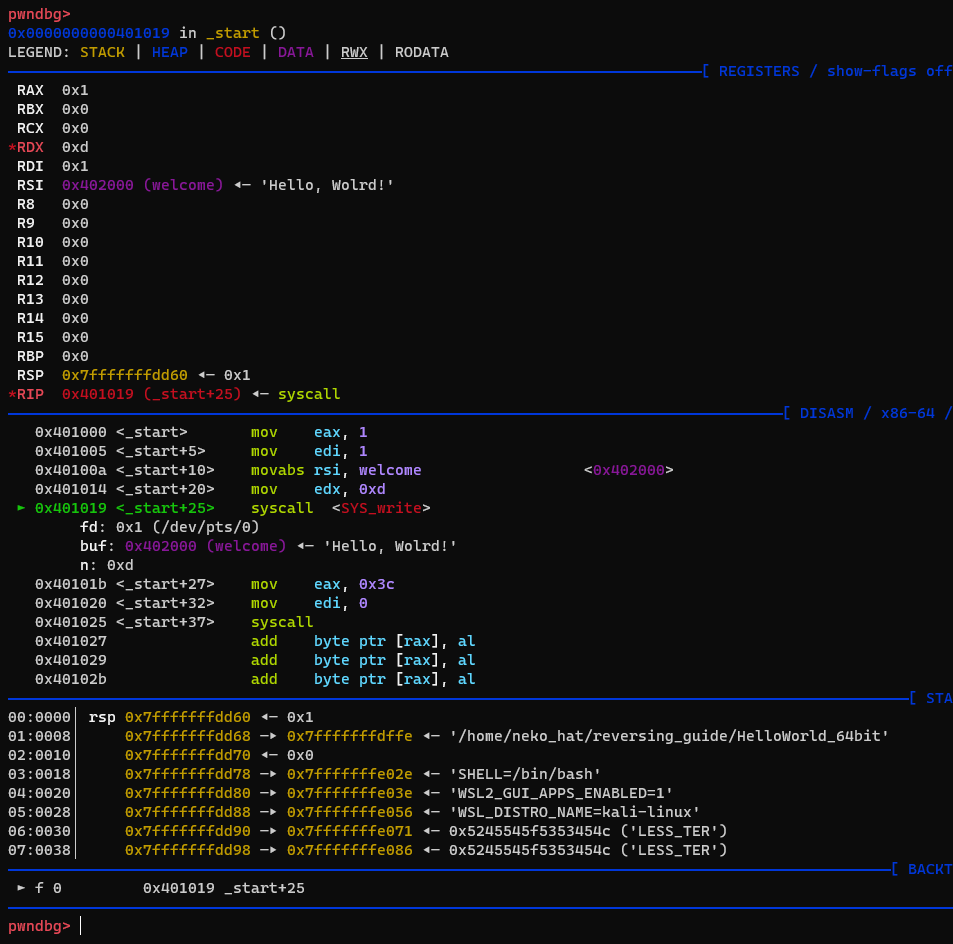
sys_write까지 실행했을 때, welcome 변수의 위치(주소)와 값을 확인 할 수 있으며, sys_write에 들어가는 인자들의 역할과 값을 확인할수 있다.

x/s <address>를 통해, 해당 주소에 담긴 값을 문자열로 출력할 수 있다.

[Image - sys_wrtie 실행]
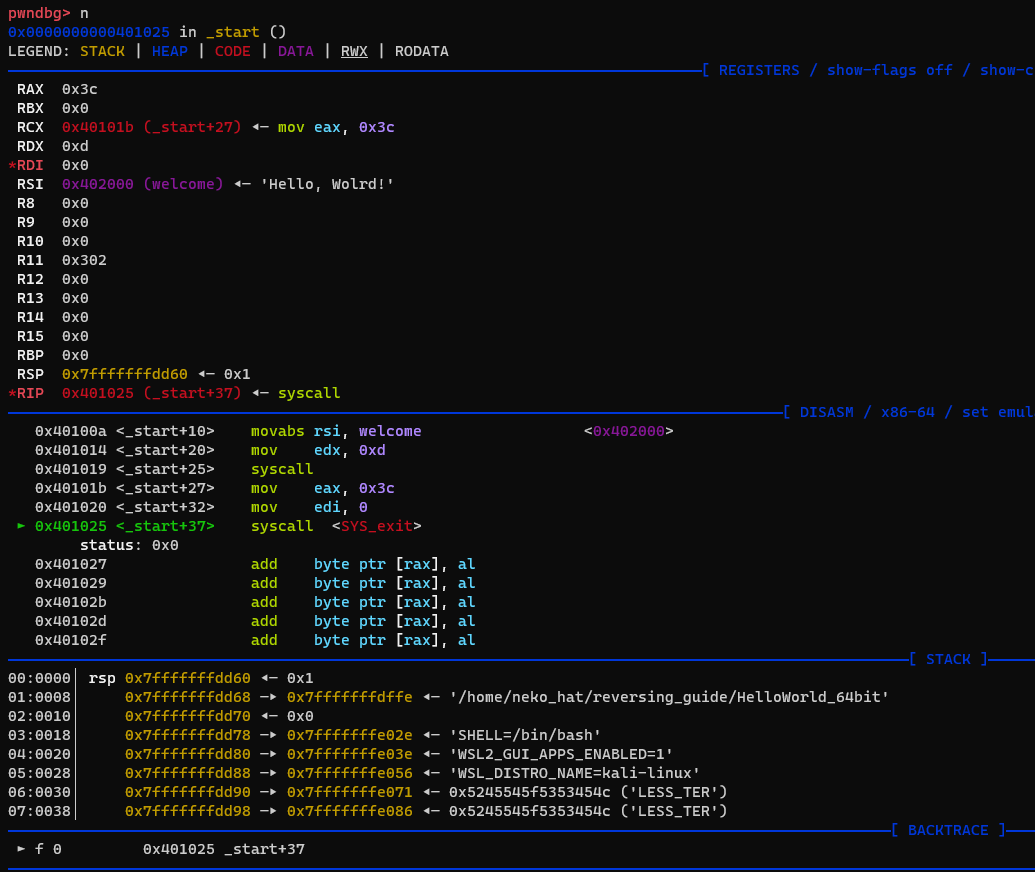
간단한 Hello, World 출력 프로그램을 (64bit 기준) 디버깅을 완료하였다.
이처럼 코드를 직접 한단계씩 실행해 가면서 분석해가는 과정을 동적 분석이라고 한다.
예제의 32bit assembly코드는 직접 따라 해보면서 Assembly를 학습하길 바란다..
메모리 구조
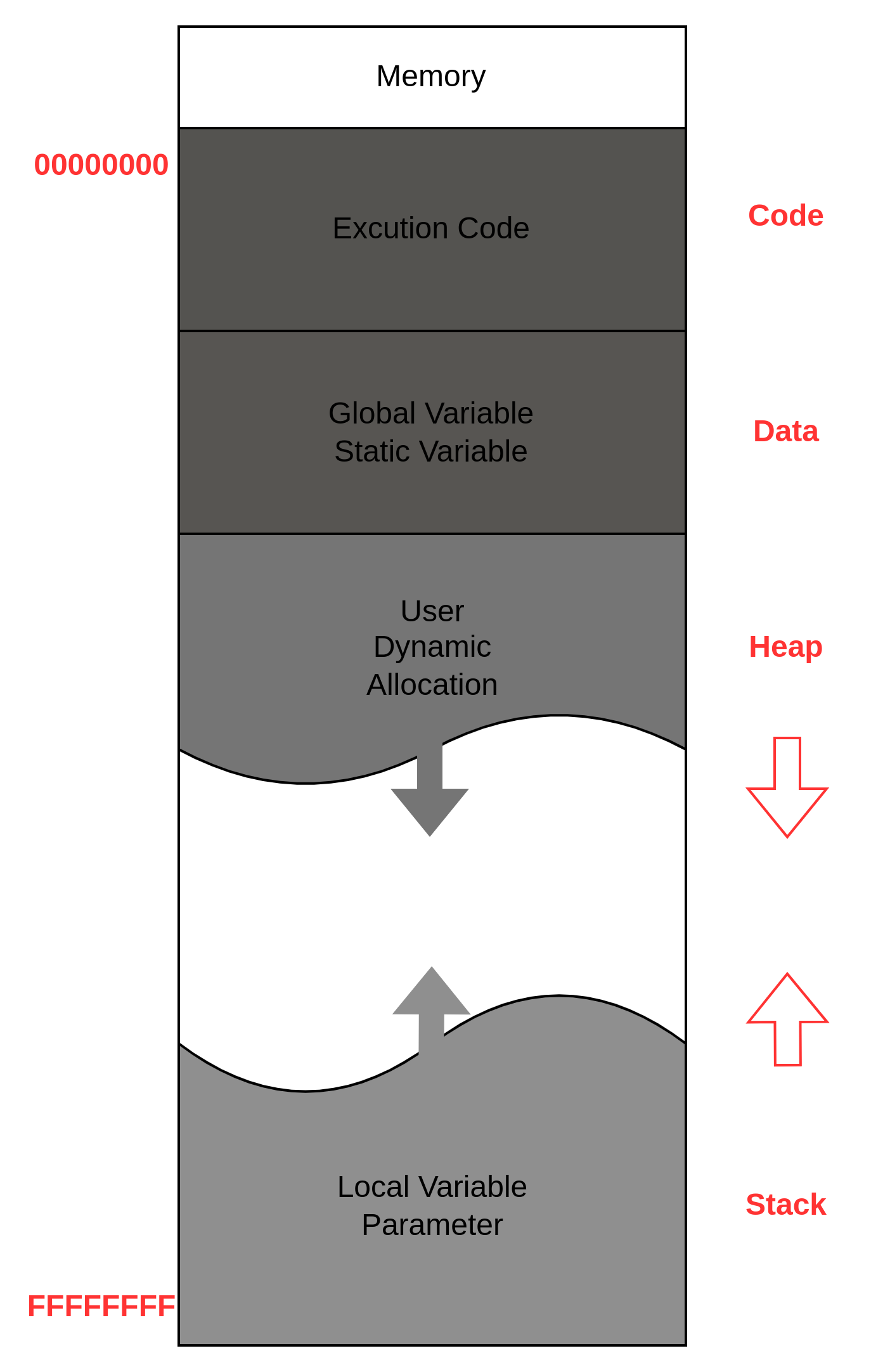
**[Image - Memory Structure]**
전반적인 메모리 구조는 위의 사진과 같다.
상위 주소에는 Code 영역 Data 영역 Heap 영역 순으로 메모리가 구성되며, 상위 주소에는 Stack 영역이 있다.
이 중 중요하게 봐야 할 영역은 Stack 영역이다.
Stack Frame
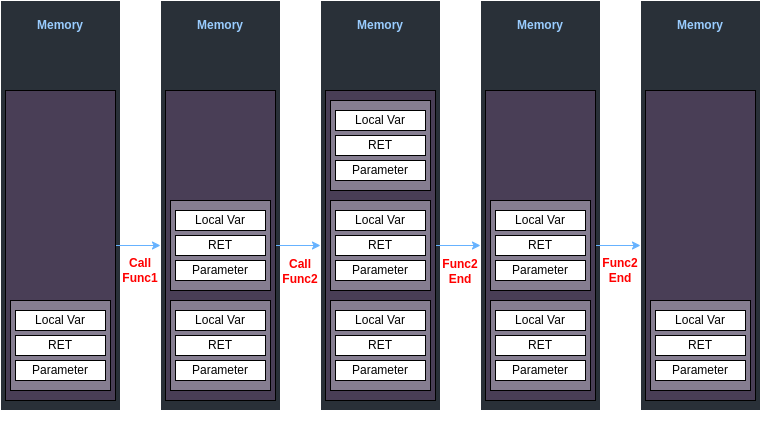
[Image - Stack Frame]
기본적인 stack frame 구조는 위와 같다.
기본적으로 함수 하나당 stack frame은 Parameter, RET, Local Variables로 구성되어 있으며, 함수가 호출 될 때마다, 해당 frame이 쌓이고, 함수가 종료되면, 해당 stack frame이 정리된다.
Assembly로 보는 Stack Frame
함수 프롤로그
우선 아래의 코드를 컴파일 한 후 살펴보자.
//gcc -o StackFrame StackFrame.c
#include <stdio.h>
int main(void)
{
char buf[0x10];
scanf("%16s", buf);
printf("%s", buf);
return 0;
}
0x10바이트의 buf에 입력값을 저장하고, buf를 출력하는 간단한 코드다. gdb에서 disassebly 코드를 살펴보자,
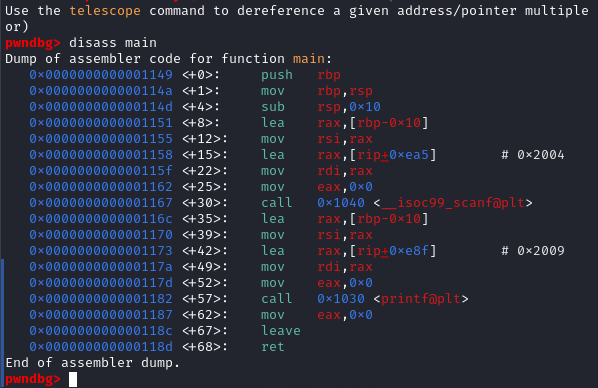
[Image - disass main]
push rbp
mov rpb, rsp
위의 두 코드를 Function Prolog(함수 프롤로그)라고 한다.
함수가 시작하면서, 본래의 base pointer값인 rbp를 push하고, rbp에 rsp값을 저장한다.
함수 호출 전의 기존 base를 stack에 저장하고, 이후 sub rsp, 0x10명령을 통해, Local Variables공간을 만들기 위한 과정인 것이다.
이 과정을 Function Prolog라고 한다.
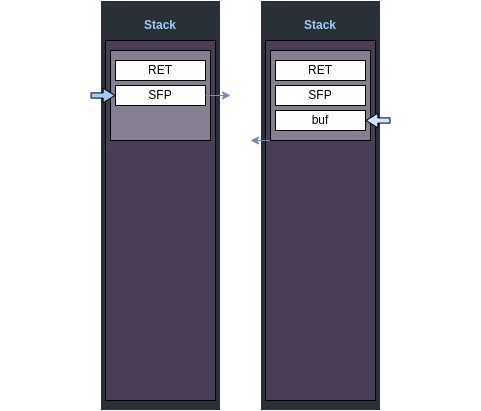
[Image - Function Prolog]
함수 에필로그
leave
ret
결론부터 말하자면, 위의 두 코드가 함수의 에필로그(Function Epilog)이다.
함수의 에필로그에서는, 함수 종료를 위해 스택을 정리하며, 함수가 호출된 곳으로 돌아간다(ret)
leave명령어는 다음의 의미를 가진다.
mov rsp, rbp
pop rbp
ret명령어는 다음의 의미를 가진다.
pop rip
jmp rip
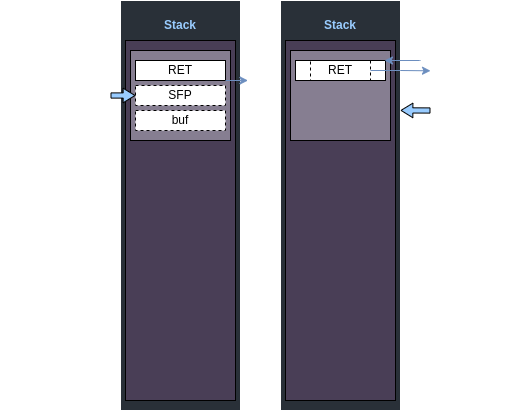
[image - Function Epilog]
함수 호출 규약
챕터 2. 리버싱 찍먹하기
2-0. 리버싱 툴 - 환경 구축하기
동적 분석 툴 (디버깅)
pwndbg 구축
#/bin/bash
#setup.sh
git clone https://github.com/pwndbg/pwndbg.git
cd pwndbg && ./setup.sh
[Code - setup.sh]
setup.sh
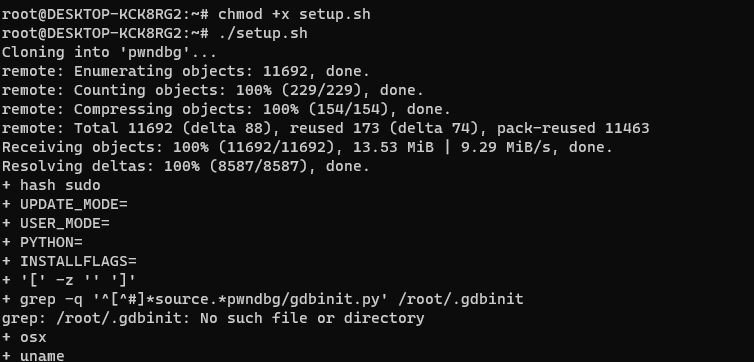
[Image - setup.sh execution]
해당 쉘 스크립트를 위처럼 실행하면, 위의 사진처럼 화면이 나오면서 설치가 진행된다.
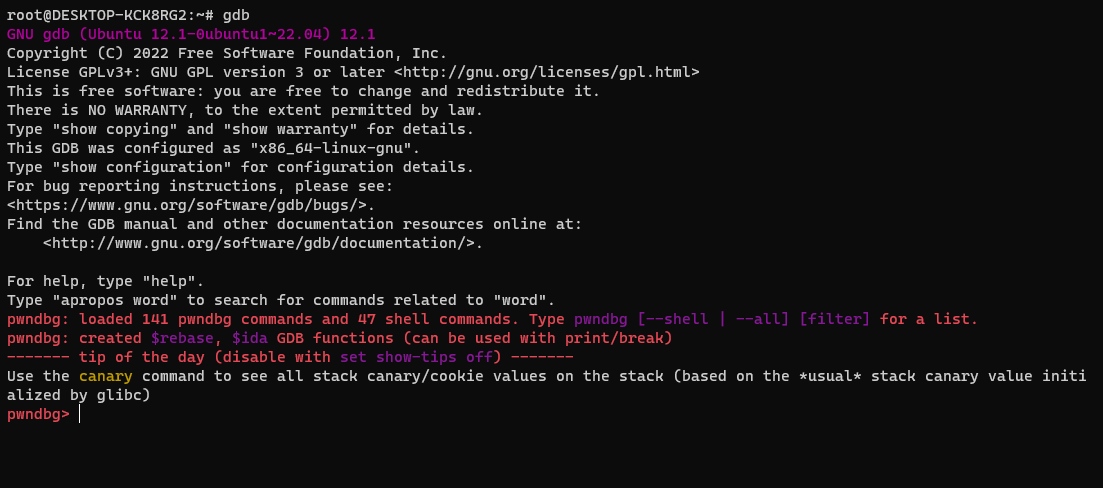
이후, gdb명령어를 통해, pwndbg>가 나오면 설치가 완료된 것이다.
아래는, 자주 사용하는 gdb 명령어이다.
| command | Detail |
|---|---|
| b(break) (*)address / function name | 해당 address, function name에 break point 생성 |
| r(run) | program 실행 (실행중 break point를 만나면 해당 point에서 멈춤) |
| c(conitnue) | program 실행 이후, break point까지 실행 |
| n(next) | step over. 한단계씩 코드를 실행하지만, 함수 내부로 들어가지 않음 |
| s(step into) | step into. 한단계씩 코드를 실행하며, 함수 내부로 들어간다. |
| p/[type] (*)[value] | [value]를 [type]에 맞게 출력. type 종류 1. s → string 2. x → hex 3. d → digit 4. u → unsigned 5. c → char |
| x/(count)[type]w [address] | 4바이트씩, [address]에 저장된 값을 tyoe에 맞게 출력 |
| x/(count)[type]g [address] | 8바이트씩, [address]에 저장된 값을 tyoe에 맞게 출력 |
| vmmap (address) | 전체 메모리 멥 출력. (address)가 속한 메모리 멥 출력 |
| pd | program이 동작중일 때, 해당 부분의 일부분 disassembly 코드 출력. |
| disass (*)address / function name | address, function name의 전체 disassembly 코드 출력. |
| start | 프로그램 시작점 (start)도달 |
| main | main 함수로 도달 |
| info reg | 현재 전체 register 상태 출력 |
| stack | rsp 기준으로 stack 영역 출력 |
radare2 설치
pwndbg(gdb)와, radare2는 취향 차이이니, 적절한 툴을 고르면 된다.
sudo apt-get update && sudo apt-get install radare2
[Code - radare2 install command] radare2는 리버스 엔지니어링을 위한 패키지이다.
대표적으로 3가지 프로그램이 내장되어 있는데, rabin2, rasm2, r2이다.
rabin2는 바이너리 정보 확인, rasm2는 어셈블러 / 디스어셈블러, r2는 전체 분석 툴이다,(동적, 정적 분석 둘다 가능)
rabin2 -I <filename>
rabin2의 간단 사용법이다.
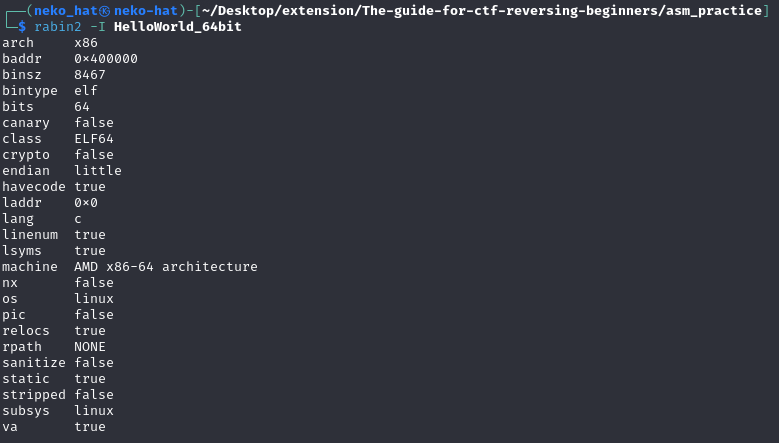
실행결과는 위와 같이, 바이너리의 Architecture, endian 형식 등 정보가 출력되는 것을 확인 할 수 있다.
r2 사용법
r2 <filename> # 정적 분석 모드
r2 -d <filename> # 동적 분석 (디버깅) 모드
r2 -w <filename> # write 모드 (주로 patch할 때 사용)
radare2 내부 분석 명령어
| Command | Detail |
|---|---|
| aa(analyze all) | 바이너리 분석 실행 |
| aaa | aa + aar, aac 명령어의 일괄 실행 |
| aac(Analyze Function Call) | 함수 호출 분석 |
| aar | Analyze len bytes of instructions for references |
| aaaa v | aaa보다 시간이 오래걸림, aaa에서 안잡히는 것이 잡힌다 생각하면 편하다. |
| afl | r2가 분석한 symbol, label 출력 |
| ~ | opcode 뒤에 붙으며, linux의 grep처럼 사용 가능하다. |
| afn name1 name2 | name2의 함수 이름을 name1으로 변경 |
| pdf (@function) | (function_name(addr)의 )디스어셈블리 확인 |
| pd (@object) | (object_name(addr) )개체 디스어셈블 |
| s function_name(addr) | 현재 탐색 위치 변경 |
| VV | 바이너리 그래프 모드 출력, [tab]키를 통해 노드 위치 변경 가능. [g]키를 통해 노드 선택, [q] 입력으로 나가기, [,]입력으로 현재 노드로 돌아가기, [x] 키로 현재 노드의 참조 위치 확인. |
| px size @addr | addr부터 size만큼 hexdump 출력. |
| fs | flagspace를 보여줌. |
| axt addr | addr에 담긴 문자열의 참조를 찾는다. |
| axt @@ str.(str_sym_name) | 플래그 지정으로 문자열 참조를 찾는다. |
| izzq | 모든 문자열 출력 (~와 연계하여 검색 가능) |
| db | Break Point 확인 |
| db function(addr) | funciton (addr)에 Break Point 세팅 |
| db -functio(addr) | Break Point 해제 |
| dr | 레지스터 상태 확인 |
| afvd | 생성된 변수 상태 확인 |
| ood (arg1 arg2) | 재실행, 인자 넣어 재실행도 가능 |
| dc | 프로그램 종료 확인(return code 확인 가능) |
x64 dbg 설치
2024.09 업데이트 예정
